CNN의 시작
CNN의 idea는 대뇌의 시각 피질 구조를 모방하는 연구에서 시작되었습니다. 고수준의 뉴런이 이웃한 저수준 뉴런의 출력에 기반한다는 아이디어입니다.
fully connected layer의 경우 image처럼 spatial structure을 가지는 data의 공간적 정보를 학습하지 못하여, cnn 구조를 활용함으로써 이 부분을 해결할 수 있었습니다.
cnn구조를 통해 고차원의 데이터가 저차원의 feature map 데이터로 변환되어 fully connected layer를 통과하는 방식으로 학습성능을 높였습니다.
CNN의 구성
basic CNN Architecture

convolution layer
-
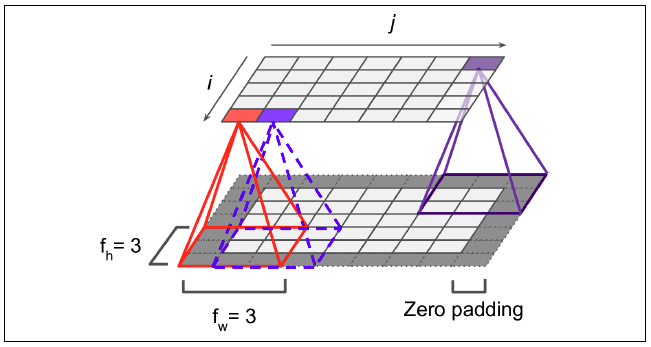
convolution 연산
연두색의 이미지를 노란색의 convolution filter(또는 kernel) 가 훑으면서 각 위치와 곱셈연산 후 합한 결과를 오른쪽 분홍색의 output에 나타냅니다. 이 때 output을 feature map이라 합니다. filter에 따라 다양한 feature map이 생성이 되고, 어떤 filter값을 사용하냐에 따라 이미지의 윤곽선, 결, shape등이 추출됩니다.
또한 filter는 weight의 집합으로 연산의 효율을 가져옵니다.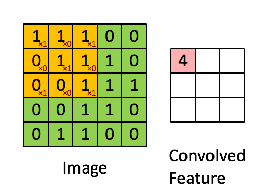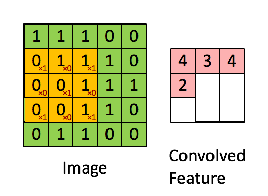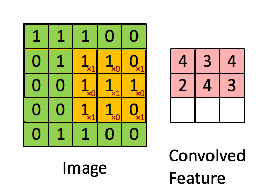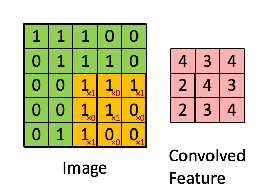
-
stride
위의 gif 경우 노란색의 filter가 한칸씩 움직이면서 연산을 하는데, 이 때 움직이는 칸을 stride라 합니다. 즉 stride =1이면 위와 같이, stride = 2 라면 두칸을 움직여 연산을 하게 되어 feature map의 크기가 2X2 형식이 됩니다.
-
padding
convolution 연산을 하게 되면 filter을 여러번 거치는 이미지 안쪽과 달리 적은 횟수만 지나치는 이미지의 테두리가 있습니다. 이런 경우 이미지의 테두리 정보를 많이 담지 못합니다. 또한 연산을 하면 할수록 map의 차원이 작아지는 단점또한 있습니다. 이를 보완하기 위해 임의의 값을 가진 pixel로 이미지를 둘러쌓는 padding기법을 활용합니다. 정보의 왜곡을 줄이기 위해 가장 많이 사용하는 방법은 0값의 pixel로 둘러쌓는 zero padding입니다.
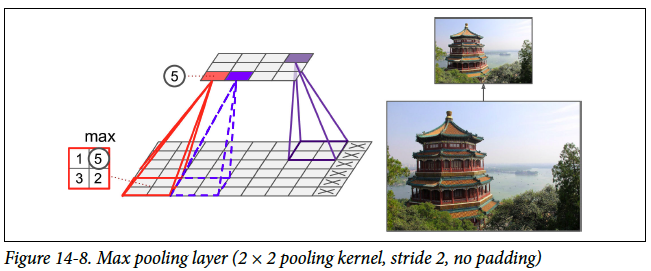
pooling layer
-
pooling
padding기법을 활용한 convolution layer를 통해 shape이 유지가 되면 fully connected layer에서 엄청난 연산량을 감당해야 합니다.
특성은 잘 유지한채, 차원을 줄여 연산부분의 이득을 보기 위해서는 pooling layer가 필요합니다.pooling은 data를 일정 크기의 창으로 분할 후 그 창안에 있는 숫자중 대표값을 다음 layer에 전달하는 방법입니다. 대표값을 어떤 값으로 정하느냐에 따라 max pooling, min pooling, average pooling으로 나뉩니다.
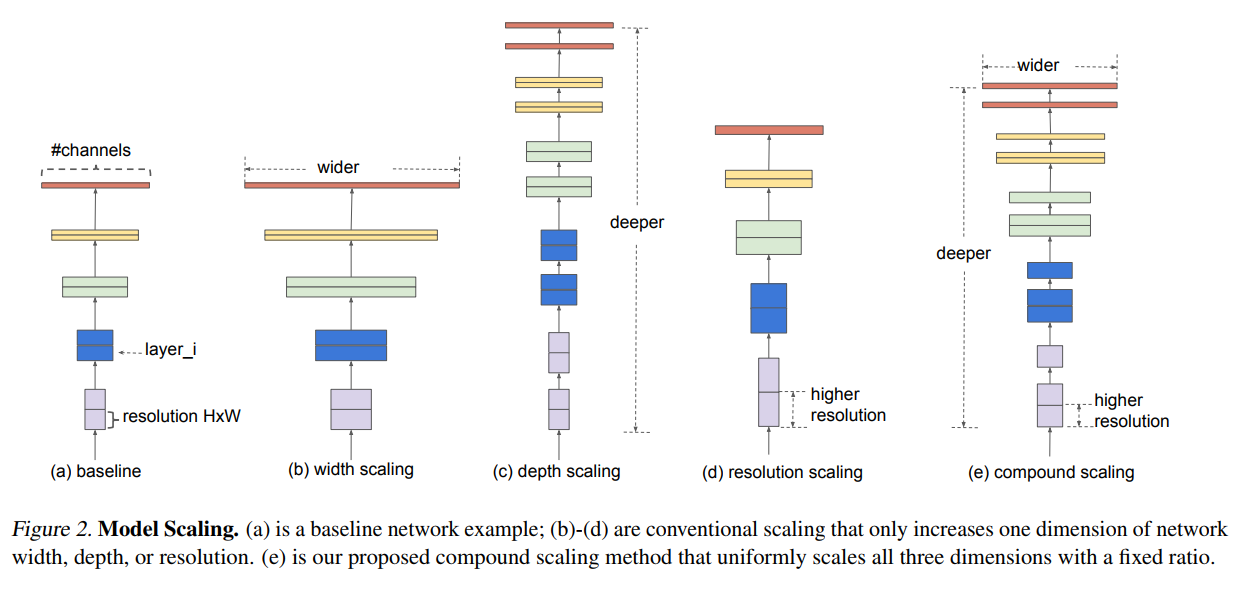
EfficientNet
기존의 CNN 모델들이 depth, width, resolution 세 기법을 각각 다뤄 모델 성능을 높혔으나, 점점 무거워지고 느린 단점이 있어 모바일환경에서도 탑재될 수 있게 효율성에 대한 논의가 활발하게 일어났습니다.
첫 주자로 MobileNet이 있으며, width와 resolution의 parameter를 활용해 성능과 전체 파라미터 수 간의 trade off관계를 적절한 지점에서 타협하고자 노력하였습니다.
2019년에 논문으로 제시된 EfficientNet은 depth scaling, width scaling, resolution scaling의 적절한 조합을 통해 적은 파라미터로 엄청난 성능을 갖추게 구성하였습니다.
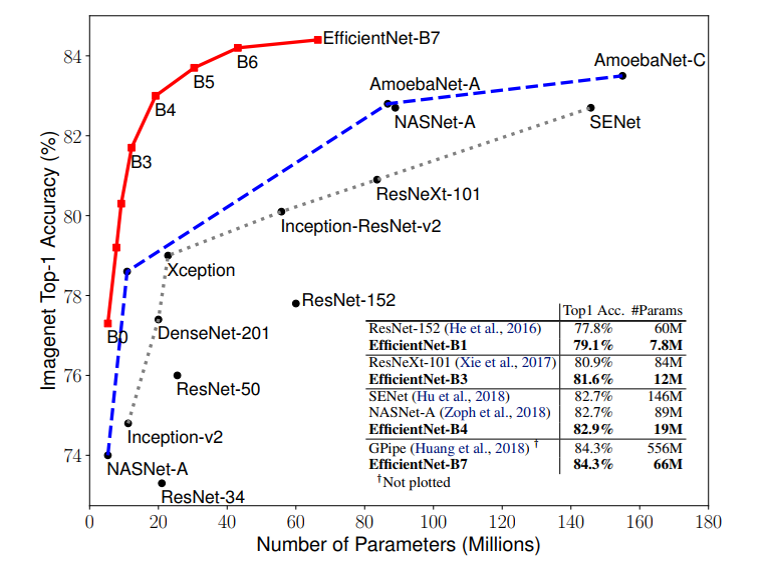
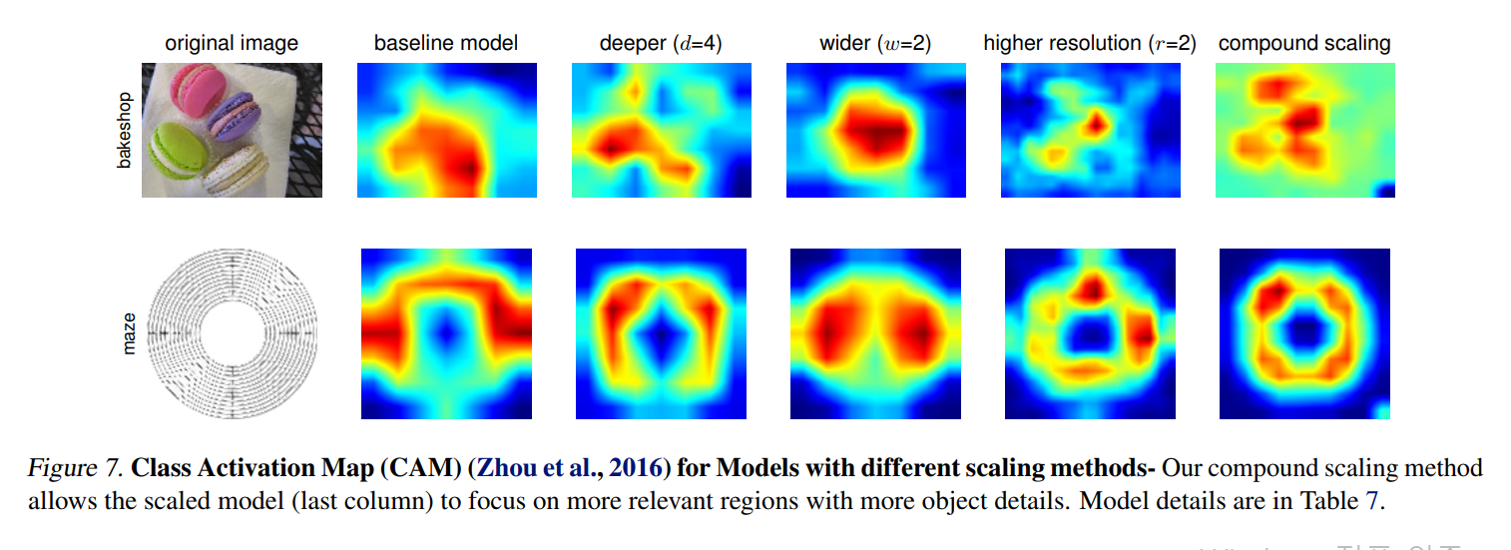
관련 기법
-
softmax
multi class classification을 가능하게 해줍니다.
-
Dropout
FC layer 또는 상황에 따라 pooling layer 뒤에 두며, 일반화를 더욱 잘하게 되어 성능향상을 기대해볼 수 있습니다.
-
Batchnormalization
Batch 단위로 한 레이어에 입력으로 들어오는 모든 값들을 이용해서 평균과 분산을 구해 Normalization 해주는 것입니다. 그를 통해 Gaussian 범위로 activation을 유지시켜 성능향상이 됩니다.