머신러닝 기초
머신러닝이란?
기존 Programming의 한계
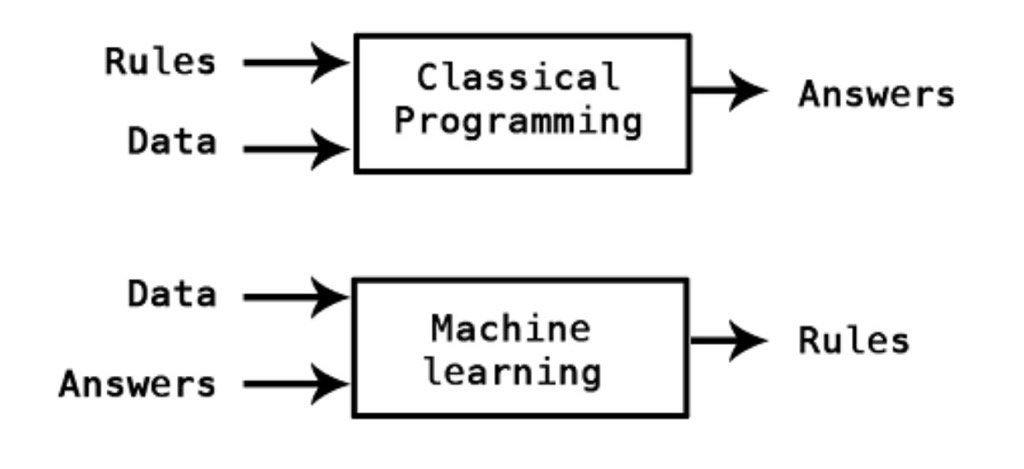
전통적인 Programming은, 사람들이 일일히 규칙을 짜서 조건문을 활용해 컴퓨터에게 input이 입력되면 그 규칙에 맞는 output을 출력하는 방식으로 코드가 작성되었습니다. 하지만 시대가 발전함에 따라 사람조차 명확하게 구분할 수 없는 정보를 통해 알고리즘을 구현해야 하거나, 구현하기에는 너무 다양한 규칙들이 필요하게 되었습니다.
따라서 1959년 ‘아서 사무엘’이 정의내린 것처럼 기계가 일일히 코드로 명시되지 않은 동작을 데이터로부터 학습하여 실행할 수 있도록 알고리즘을 개발하는 머신러닝이 등장하게 되었습니다.
현대에 와서 머신러닝은 AI의 한 분야로, 데이터의 feature와 label이 주어졌을 때, 컴퓨터가 스스로 학습하고 input-output 사이의 규칙을 찾아 생성하는 알고리즘과 기술을 개발하는 분야를 말합니다.
머신러닝 프로세스
- 문제정의:
만들고자 한 알고리즘 모델을 어떻게 사용할 지 정의합니다.
- 모델을 가지고 해결할 문제의 목표는 무엇인가
- 목표를 수행하는데 제약조건은 무엇인가
- 어떤 머신러닝 알고리즘을 선택할 것인가
- 문제해결의 성공 및 실패의 척도로 어떤 성능지표를 활용할 것인가
-
데이터 수집: 다양한 방법으로 모델을 학습시킬 데이터들을 수집합니다.
-
탐색적 분석과 시각화: 상관관계 등 다양한 분석기법을 통해 feature분석을 하여 데이터의 오류확인, 데이터의 특징/패턴, 문제/한계를 파악합니다. 또한, 데이터를 재수집하거나 추가수집하고, 가설을 설정 후 기계학습 모델에 입력할 속성을 선택합니다.
- 데이터 전처리:
활용 목적에 따라 데이터들을 필터링을 하여 분석시간을 단축하고, 저장공간을 효율적으로 사용하고, Missing value와 중복을 제거하여 데이터 품질을 개선합니다.
- Null 값, 중복값 처리
- 데이터 형식에 따른 Encoding
- 이상치 및 특이값 제거
- Rescaling - Normalization
-
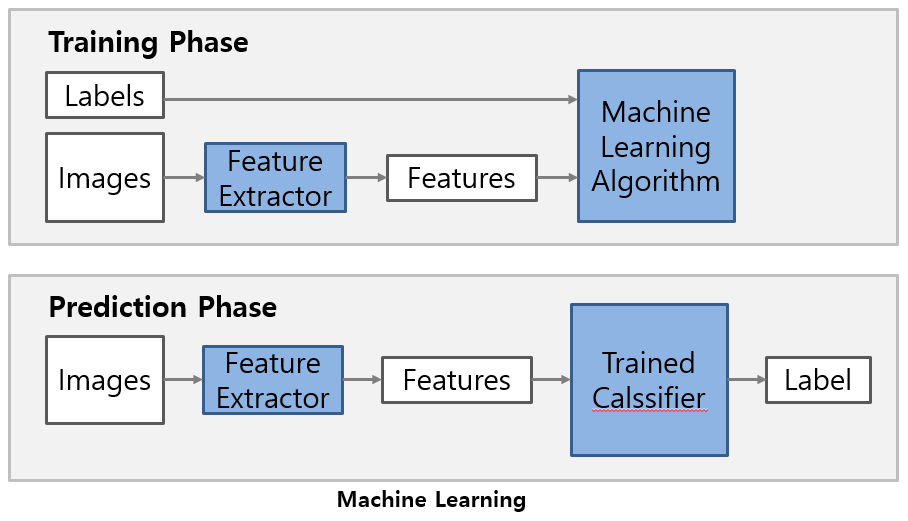
모델 생성: 예측 알고리즘을 선택하여 아래의 그림처럼 train data set과 test data set으로 나누어 학습시킵니다.
-
모델 세부 튜닝: 여러 파라미터를 조정해가며, 성능지표를 활용해 최상의 모델을 선택합니다.
- 평가 및 분석: test data set을 통해 모델을 평가하고, output에 관여한 특성이 어떤 것인지 분석하며, 설정했던 가설에 대한 평가를 내립니다.
다양한 Scaling기법 알아보기
- StandardScaler:
데이터들을 평균은 0, 분산은 1이 될 수 있도록 scaling합니다.
- RobustScaler:
median이 0, quartile을 사용하여 이상치에 영향받지 않도록 scaling합니다.
- MinMaxScaler:
모든 값을 0~1 사이에 위치하도록 scaling합니다.
- Normalizer:
위의 Scaler들은 feature중심으로 column의 통계치를 사용한다면, normalizer은 row마다 각각 정규화합니다. 유클리드 거리가 1이 되도록 데이터를 조정합니다.
머신러닝 활용사례 및 도전과제
활용사례
아마존의 맞춤식 제품 추천, Facebook의 안면인식, Google Maps의 빠른 경로 추천 등 다양하게 활용되고 있습니다.
도전과제
- 충분하지 않은 양의 훈련 데이터 -> 충분한 데이터 확보
- 대표성이 없는 훈련 데이터 ->
- 낮은 품질의 데이터
- 관련없는 특성
- 훈련데이터 과대적합, 과소적합
모델의 성능을 높이기 위해서는 위의 과제들을 해결해야 합니다.
SVM(Support Vector Machine)
지도학습 중 분류문제를 해결하기 위한 모델입니다. SVM은 학습을 통해 결정되는 Decision Boundary를 사용하여 data에 대해 분류를 하게 됩니다. 그렇다면 Decision Boundary를 결정하는 방법에 대해서 살펴보겠습니다.

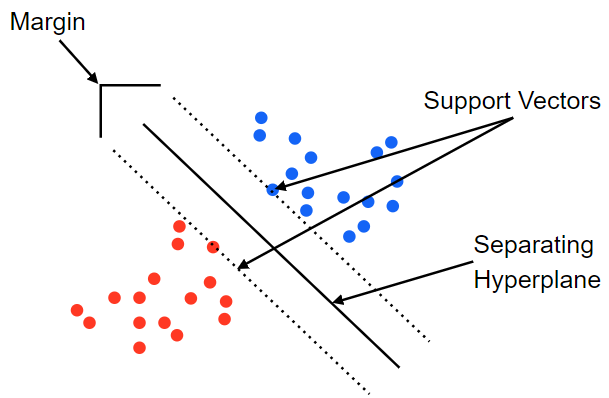
Decision Boundary
Supprot Vectors란 Decision Boundary와 가까이 있는 데이터의 위치를 의미하는데, SVM모델은 이 Support Vector와 Decision Boundary 사이의 거리, 즉 Margin값이 최대값을 갖게할 수 있도록 Decision Boundary를 결정합니다. 안정적으로 데이터를 분류하기 위해서는, 분류하기 어렵게 붙어 있는 데이터들을 가를 필요가 있고, 그러기 위해서는 Margin을 크게 가져 test data가 입력이 되더라도 여유를 가진다고 생각하면 될 것 같습니다.
SVM 속성의 tradeoff
SVM 분류모델에서 오류발생수와 margin값은 tradeoff관계를 가집니다. margin값을 최대로 하면(soft margin) 일부 특수 케이스에 대해서는 오류가 발생할 수 있습니다.(underfitting) 하지만 오류가 절대 발생하지 않도록 하려면 margin값을 조절할 필요가 있습니다.(hard margin) 하지만 margin값을 줄여 학습데이터 오류 발생수를 감소시키면, overfitting문제에 직면하게 됩니다.
SVM의 장점
- 범주, 수치 예측문제에 사용합니다.
- 오류 데이터의 영향이 적습니다.
- 과적합 되는 경우가 적습니다.
- 신경망보다 사용하기 편합니다.
SVM의 단점
- 최적의 decision boundary를 찾다보니 여러 개의 조합 테스트가 필요합니다.
- 학습 속도가 느립니다.
- 해석이 어렵고 복잡한 블랙박스 모델입니다. 어떤 특성때문에 Decision Boundary가 결정이 났는지 파악하기 어렵습니다.
Reference
https://ikkison.tistory.com/49
https://m.blog.naver.com/yoonok415/221794664696
https://hyeshin.oopy.io/6c78ad29-c65e-448e-9211-212c4510fa80
https://tensorflow.blog/%ED%95%B8%EC%A6%88%EC%98%A8-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-1%EC%9E%A5-2%EC%9E%A5/1-4-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D%EC%9D%98-%EC%A3%BC%EC%9A%94-%EB%8F%84%EC%A0%84-%EA%B3%BC%EC%A0%9C/
https://homeproject.tistory.com/3
https://muzukphysics.tistory.com/entry/ML-8-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-SVM-%EA%B8%B0%EB%B3%B8-%EA%B0%9C%EB%85%90%EA%B3%BC-%EC%9E%A5%EB%8B%A8%EC%A0%90-Support-Vector-Machine
https://hleecaster.com/ml-svm-concept/